

Last time I introduced Drum-Buffer-Rope, Eliyahu Goldratt’s novel approach to manufacturing production.
To understand why DBR was so revolutionary, let’s examine how it proposed to use the mechanism of time to limit work-in-process and maximize flow through a system.
Like any flow system, the question Drum-Buffer-Rope seeks to answer is, “How do we operate the system to achieve maximum throughput?” Throughput, as you’ll recall, is the number of units that can be produced by a production process within a certain period of time.
Goldratt’s answer was to use three time-based leverage points to accomplish that:
- The processing rate of the bottleneck
- Strategically placed buffers
- The timing of “release of materials”
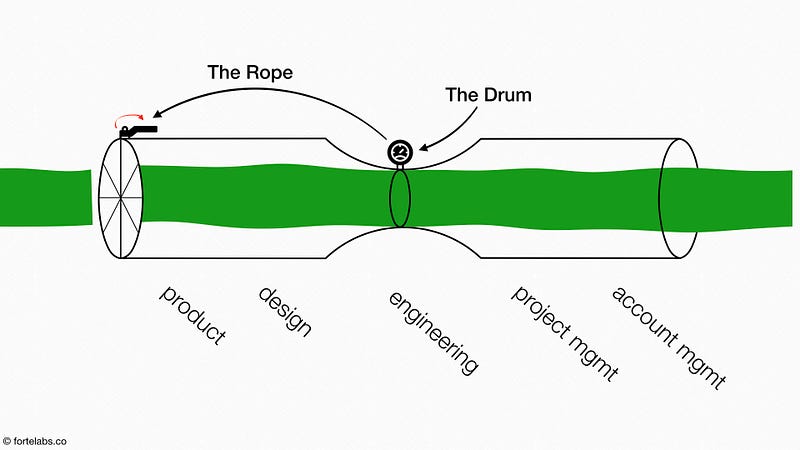
The processing rate of the bottleneck is the “Drum” that determines the pace at which the entire system should work (like a drummer in a marching band helping the whole group step in sync). Picture it as a meter which detects when a part moves through the bottleneck.
Once a part is finished moving through the bottleneck, the Drum sends a message (via the “Rope”) to the start of the production line (at the far left of the pipe) telling it to “release” a new piece of work-in-process.
In other words, the Rope is the signal that “pulls” a new item of work into the pipe only when an item is processed by the bottleneck (the same role played by Ohno’s kanban cards earlier).
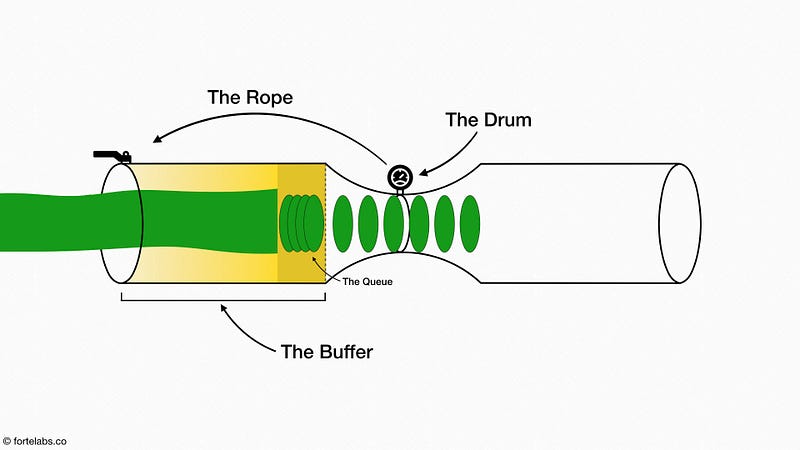
There is one last element to add, which is the Buffer.
Buffers in general are an important element in many systems: the wall of a cell is a buffer against the outside environment; the shocks on a car are a buffer against the bumps in the road; the two hours you allow when arriving at the airport are a buffer against unexpected delays. Any part of a system that needs protection from uncertainty, variation, or disturbances in the environment, while still interacting with that environment, requires some sort of buffer.
The need for a buffer in manufacturing becomes obvious when we remember that the capacity of the whole system is equal to the capacity of the bottleneck. What this means is that the “cost” of a broken-down machine (or sick employee) at the bottleneck is not the time lost for that one work center. It is the burn rate for the entire company. Every single minute of time lost at the bottleneck must be counted as a minute lost for the entire system.
Therefore, it is imperative that the bottleneck never goes idle for any reason. The only way to do that is to stockpile lots of work-in-process in a queue in front of it, so it will always have something to work on even if the flow from upstream gets temporarily interrupted.
This is exactly the purpose of the Buffer: to protect the bottleneck from disturbances in the upstream flow of work, evening out the variations and doling out chunks of work from the queue in exactly the quantity and at the pace required to keep it occupied.
The principles of flow we’ve examined so far imply a management philosophy: no company should take on more work than their bottleneck can process. The job of management is to determine the capacity of their bottleneck, fill it, and then allow no more projects to begin until one is completed.
Another way of saying this is that for even one part of a system to be fully utilized (the bottleneck), every other part must have excess capacity. This is in such direct contradiction to the way most organizations are run that Goldratt described this as the single biggest mindset change in adopting the Theory of Constraints.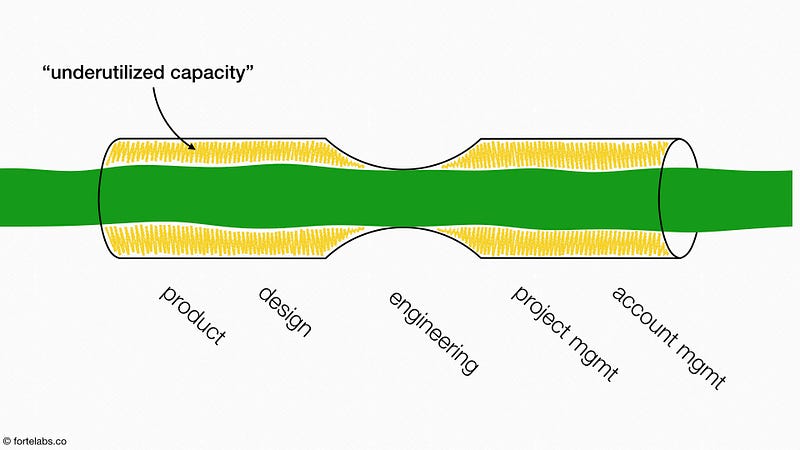
The end result of ignoring these principles is familiar to many organizations. If someone reveals or even suggests that they don’t have enough to do, we find something for them to do. If we can’t find anything, we let them go.
So of course, no one ever has “nothing to do.” Any excess capacity that may appear is hidden, obscured in the fog of busywork, which expands to fill all available time. Later, when an opportunity for real value-adding work comes along, they’re “busy.”
Seeing their people with no time, and concluding the problem must be a “lack of capacity,” management hires yet more people. Yet because they likely don’t add to the capacity of the bottleneck, these extra people are left with nothing to do but busywork.
The ironic consequence of not allowing people to have excess capacity is that the company is left with tremendously more excess capacity than ever before.
The power of DBR is that it doesn’t bother with complex graphs, doesn’t require total surveillance, and doesn’t prescribe exactly how work should be performed. It focuses instead on system dynamics, using three time-based leverage points plus feedback loops to maximize overall flow instead of capacity.
By using the mechanism of time, Goldratt unlocked the power of flow and allowed its principles to be applied far beyond the world of manufacturing — to project-based consulting, to sales and marketing, to retail and healthcare services, and eventually, to telecommunications and software development.
In all these diverse fields, work moves not through the sequential, linear flow of an assembly line, but the even more rigid, even more linear flow of time.
With that insight, we are ready to begin applying ideas born in the greasy world of Industrial-era factories to the most cutting-edge knowledge work of today.
Follow us for the latest updates and insights around productivity and Building a Second Brain on X, Facebook, Instagram, LinkedIn, and YouTube. And if you're ready to start building your Second Brain, get the book and learn the proven method to organize your digital life and unlock your creative potential.