

In the previous post, I explained Drum-Buffer-Rope (DBR), the original application of TOC to production environments like manufacturing.
This might all seem like old, outdated manufacturing lore that has nothing to do with the present day. Think again. Let’s take a look at a real-world example that brings together all the ideas we’ve covered in the series so far at one of the world’s most innovative companies: Microsoft.
The story begins with a young program manager, Dragos Dumitriu, deciding to take on a challenge: applying the principles of the Theory of Constraints to turn around the worst performing software development team in one of the company’s eight IT groups.
By the time he was finished nine months later, the team was the best performing in its business unit, with an improvement in productivity of 155%, lead time reduced from five months to two weeks, and due date performance improving from near zero to over 90%.
XIT Sustained Engineering was responsible for maintaining over 80 applications for internal use by Microsoft employees (or “customers”) worldwide. This involved development and testing for small change requests (often bug fixes). The first quarter of 2005 saw the worst ever productivity from the team — the backlog exceeded capacity by a factor of five (and growing). Needless to say, the four internal customer groups who needed their applications maintained weren’t happy.
XIT typically received about one change request per day, or 85 per quarter. But the team of three developers had an average capacity of only 6.5 each (about 20 total), leading to a throughput over the previous quarter of only 17 completed requests:

When a new change request arrived, it needed to be evaluated for a rough time estimate. The agreement between XIT and its internal customers specified that this estimate had to be performed within 48 hours, which meant that it had to be expedited as a top priority.
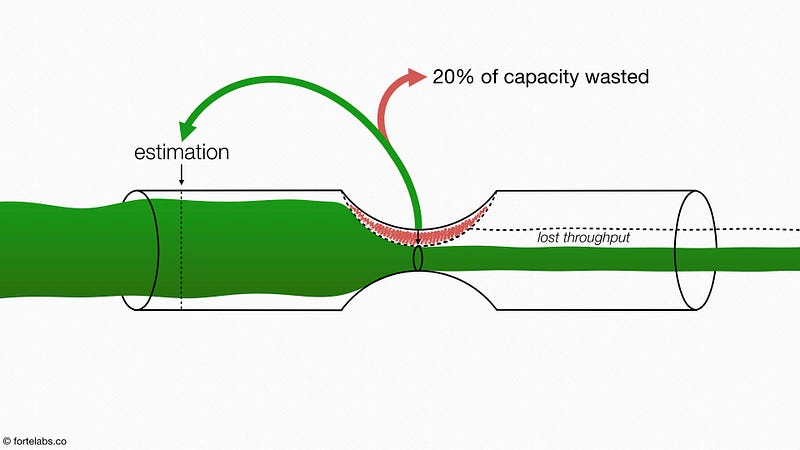
Here we already begin to see the problem — producing an estimate required four hours each from a developer and tester, meaning that each change request sucked one full day of productivity out of the system. One request per day, one day per request — they were standing still. Just producing estimates was taking up to 40% of their total capacity:

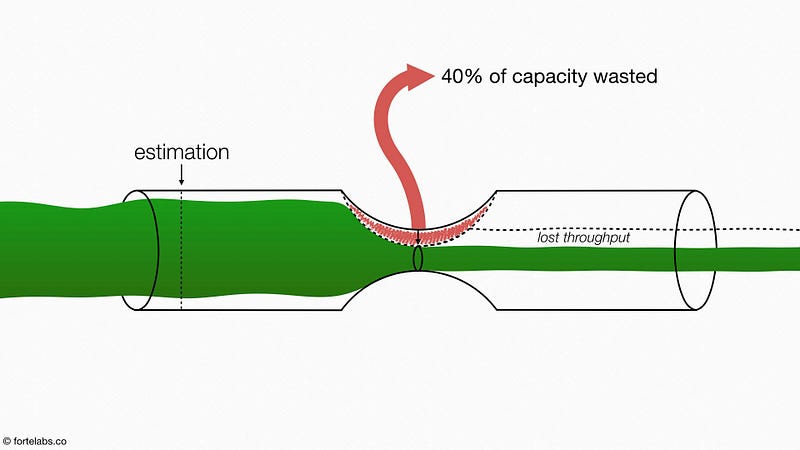
It gets worse. Historical data showed that only about 50% of requests were actually completed by the team. The other 50% were either too big, too expensive, or too late. Only half of the estimates the developers produced actually contributed in any way to throughput, which means that 15–20% of the team’s total capacity was being wasted.
And worse still, much of the evaluation work they completed would never be used, because so much time had passed by the time work began that it had to be done again.
Which means that nearly all of the evaluation work was waste:
Because the backlog was so large, it had to be continually reprioritized. The monthly prioritization meetings got more and more stressful, as customers started fighting to have their priorities included. Trust broke down as they stopped believing their requests would ever be acted on without Severity 1 urgency.
Sound familiar?
Dumitriu came up with three interventions in collaboration with David Andersen, one of the first consultants to apply TOC to software development. They may seem like common sense in retrospect, but the conceptual framework of TOC served as a belief-reinforcer and permission-giver for delicate changes to how the team worked and communicated with its customers.
The first intervention was to add a buffer right in front of the development team. Remember that a buffer is like a “waiting area” or queue where new pieces of work wait until they are ready to be processed. The purpose of the buffer is to stop new requests from flowing directly into the bottleneck, where developers have to interrupt what they’re doing to handle them. Instead, 8 “slots” in the buffer would hold new requests until a developer was ready to review them.

The addition of a buffer had several positive effects:
- Project managers would only commit to a delivery date once a request was estimated, scoped, and assigned to a slot in the queue, which allowed them to set realistic expectations and timelines
- The incoming flow of new requests was “choked” to a level that the team could actually consume, which reduced the lead time per request since developers were focused and single-tasking instead of switching between priorities
- The monthly prioritization meetings became much less stressful since everyone knew they only needed to fill a “batch” of 8 new requests
The second intervention was to stop providing upfront estimates. Every change request was assumed to take an average of five days (with a couple extra rules for edge cases). This was only possible after the buffer had reduced and stabilized the average time needed per request.

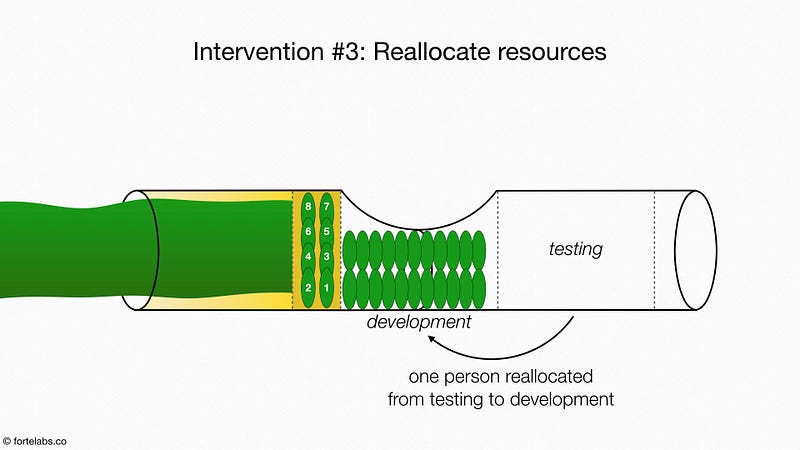
The third intervention was to reallocate resources to optimize the bottleneck. One person was reassigned from testing to development, changing the ratio from 3:3 to 4:2.
Once bottleneck capacity had been fully utilized and expanded using available resources, it was time for the final step: further increase bottleneck (and therefore system) capacity by hiring more developers. Note that as important as it is to add capacity to the bottleneck, it makes no sense to do so until existing capacity is being fully used. Otherwise, it’s like adding lanes to a freeway while a sofa blocks the express lane.

Total throughput of the XIT Sustained Engineering team increased from 17 requests per quarter to 56. The backlog was reduced from 80 requests to under 10, and the average cost per request fell from $7,500 to $2,900. The customers were happy again.
It is often assumed that, if TOC applies at all to modern knowledge work, it must require the most advanced applications. Using a simple approach like Drum-Buffer-Rope in this case shows that much of what constrains the productivity of software engineers (and by extension, other knowledge workers) is not related to the details of how they perform their work, but to the management, planning, scheduling, and queueing of work.
In other words, engineering may be the bottleneck of the whole organization, but management is the bottleneck to improving engineering.
Follow us for the latest updates and insights around productivity and Building a Second Brain on X, Facebook, Instagram, LinkedIn, and YouTube. And if you're ready to start building your Second Brain, get the book and learn the proven method to organize your digital life and unlock your creative potential.