
Personal Knowledge Management (PKM) is the practice of capturing the ideas and insights we encounter in our daily life, whether from personal experience, from books and articles, or from our work, and cultivating them over time to produce more creative, higher quality work. I teach people how to master PKM in my online course Building a Second Brain.
By collecting our knowledge in a centralized place outside of our own heads, we can create an engine of creative output – a “second brain” – to advance a career, build a business, or pursue a passion. By making this knowledge digital, we can reap the benefits of searchability, backups, syncing between devices, sharing with others, and more.
But there’s one aspect of personal knowledge management I haven’t fully addressed, which is tags. In the past, I criticized tags harshly as being too taxing, overly complicated, and low value for the effort required. I advised people not to use tags to manage their knowledge, favoring notebooks or folders instead.
But I’ve changed my mind since then. Over several years of observations, findings, and experiments, I’ve come to believe that tags could be the missing link in making our knowledge collections truly adaptable – able to reorient and reconfigure themselves on the fly to enable any goal we wish to pursue.
Let me tell you what I believe is required to unlock the immense potential of tagging for personal knowledge management.
Hierarchies vs. networks
There are two kinds of basic structures that permeate reality: hierarchies and networks.
We currently live in a “network age,” as the internet and digital technology have given people the ability to connect and collaborate directly with each other across the world. Organizational charts are flattening, social movements rise and fall without central direction, and borders of all kinds are becoming more porous as the internet flows across them.
Our infatuation with networks has led to a widely held belief that the era of hierarchies is over. That we now live in a golden age of individual self-expression and autonomy, uniquely enabled by networks. In this view, hierarchies are inherently restrictive, oppressive tools of control that we should abolish whenever possible, and networks are inherently open, democratic tools of personal liberation.
The history of information revolutions tells quite a different story. Networked information is not an exclusively modern invention, and hierarchies are not necessarily doomed. The tension and the balance between them has existed for millennia. Today we’re witnessing only the latest chapter in this history.
Definitions
But first, let’s settle on definitions.
A hierarchy is a system of nested groups. A standard organizational chart is a hierarchy, with employees grouped into business units and departments reporting to a centralized authority. Other kinds of hierarchies include government bureaucracies, biological taxonomies, and a system of menus in a software program. Hierarchies are inherently “top-down,” in that they are designed to enable centralized control from a single, privileged position.
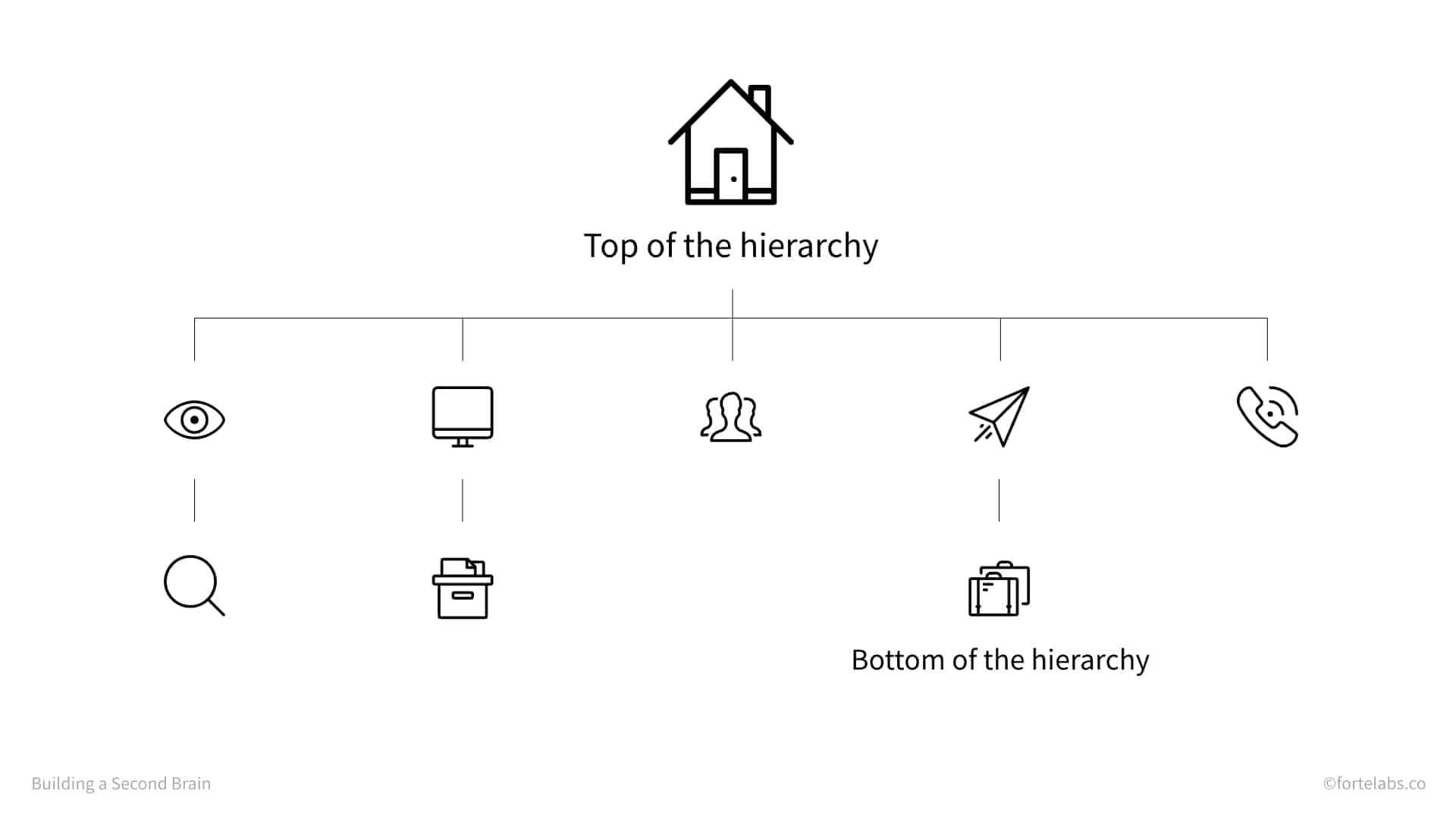
A network, by contrast, has no “correct” orientation, and thus no bottom and no top. Each individual, or “node,” in a network functions autonomously, negotiating its own relationships and coalescing into groups. Examples of networks include a flock of birds, the World Wide Web, and the social ties in a neighborhood. Networks are inherently “bottom-up,” in that the structure emerges organically from small interactions without direction from a central authority.
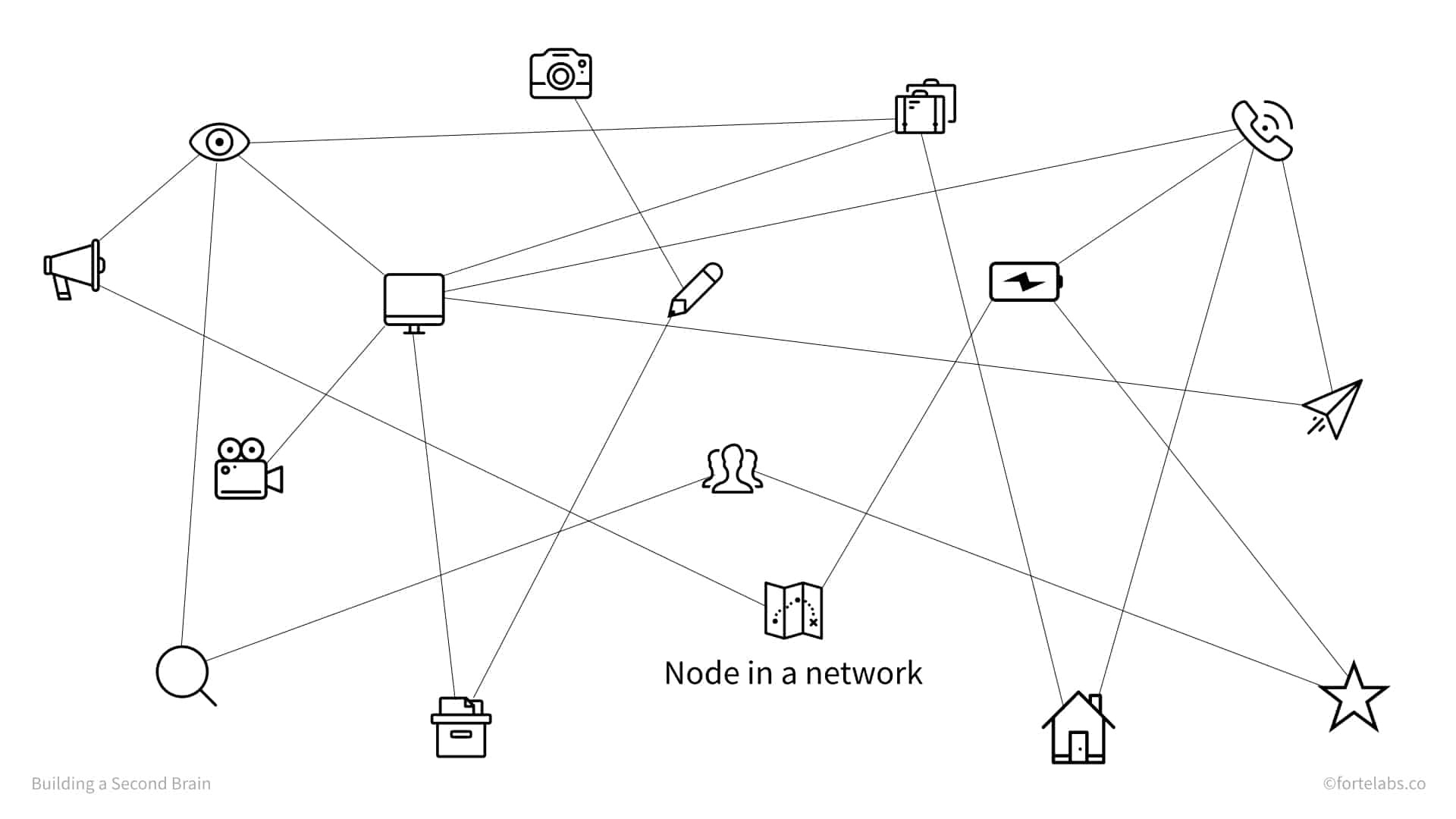
These two structures are not mutually exclusive – in fact, they coexist everywhere. A company might have a formal organizational chart that is hierarchical, but at the same time, it is permeated by a network of “influence relationships” between employees that don’t respect official boundaries.
There is a network in the hierarchy.
Even the internet, the most prototypical example of a pure network, requires hierarchies to function. The servers that send us data are organized hierarchically, as are the packets of data they send. The web browsers that allow us to view webpages are designed hierarchically, as are the menus we navigate to find what we’re looking for.
There is a hierarchy in the network.
Hierarchies and networks are constantly giving rise to each other
Not only do networks and hierarchies peacefully coexist, they are constantly giving rise to each other. They are like symbiotic organisms, each one balancing and complementing the other.
One theory of the origins of life on Earth envisions the first multicellular life forms as self-organizing networks of simpler, single-cell organisms. First coming together to exchange byproducts and for mutual protection, over time a hierarchy emerged: a complex nervous system. These complex organisms in turn coalesced into even higher-order social networks, which provided even more survival benefits.
The online encyclopedia Wikipedia has long been praised for its crowdsourced, populist approach to gathering knowledge. But in recent years, Wikipedia’s rapid growth has forced it to develop a series of hierarchical control systems, such as a governance body and approval process. Networks can self-organize and spawn novel ideas and connections, but a hierarchy is required to give it form and structure to survive in the long term.
As John Seely Brown and Paul Duguid write in The Social Life of Information, “While it’s clear that self-organization is extraordinarily productive, so too is formal organization. Indeed, the two perform an intricate (and dynamic) balancing act, each compensating for the other’s failings. Self-organization overcomes formal organizing’s rigidity. Formal organization keeps at bay self-organization’s tendency to self-destruct.”
Hierarchies are effective for large-scale, slow-moving efforts in relatively predictable environments. They enable centralized direction and tight synchronization between many moving parts. In times of command and control warfare, mass producing a standardized product, or managing a vast bureaucracy, only a hierarchy will work.
Networks are good in small-scale, quickly changing situations in unpredictable environments. They favor adaptability, flexibility, and individual autonomy. In times of guerrilla warfare, revolutionary innovation, or open-ended creativity, networks are indispensable.
Hierarchies and networks balance each other
Throughout history, every time we reach the limits of one form, the other emerges as a counter-balance.
Francis Bacon’s scientific method, first introduced in the 17th century, was a bottom-up, networked approach to building scientific understanding. Scientists were expected to reach their own conclusions and then verify each others’ work directly through scholarly networks. This approach contrasted with the tradition of receiving knowledge from hierarchical authorities like the church and state without questioning.
In the 18th century, the encyclopedia movement promoted most famously by Denis Diderot moved in the opposite direction. So much knowledge was being produced from so many sources that people sought a top-down categorization to make sense of it all. Thus the modern encyclopedia was born.
In modern times we face a similar dilemma. The explosion of digital information on the internet has overwhelmed every tool we have for classifying and categorizing it. Only a bottom-up, automated tool is capable of making sense of so much data. Google’s PageRank algorithm made it possible to assign importance and meaning to a webpage not through human judgment, but by analyzing keywords and hyperlinks. It is a bottom-up, algorithmic approach to making meaning out of the network.
Hierarchies are resilient
Despite the popularity of networks in the Information Age, the hierarchy persists as a simple, consistent way to organize knowledge.
Numerous studies (Bergman et al. 2008; Fitchett and Cockburn 2015; Teevan et al. 2004) have found that people strongly prefer to navigate their file systems manually, scanning for the file they’re looking for, as opposed to searching. Manual navigation gives people a concrete structure to navigate, with folders and labels giving them visual feedback and control in incremental steps (Jones and Dumais 1986).
Searching relies on declarative memory – remembering and entering the precise contents of a file – which is a higher-level brain function that consumes a lot of energy. Manual navigation, on the other hand, relies on procedural memory (Barreau 1995) – specifying partial information, recognizing clues and context, and receiving feedback (Teevan et al. 2004; Jones 2013). This kind of memory uses “older” parts of the brain that developed to navigate spatial environments, and thus comes to us more naturally.
In other words, it’s clear that hierarchies aren’t going away, even as our search tools become ever more sophisticated.
But the weakness of hierarchical systems is that knowledge remains siloed from other ideas that could spark interesting connections. Adding a network to our file systems can help us preserve the benefits of hierarchy, while infusing it with cross-connections and associations.
This is the true purpose of tagging in the modern digital age. Not to replace the hierarchy, but to complement it. Tags allow us to create alternative pathways that tunnel through the walls of our siloed folders, while leaving them just as we left them.
The intelligent use of space – tags as virtual spaces
Thinking of tags as “tunnels” through our knowledge connection allows us to make use of our rich understanding of humans’ relationship to physical space. Tunnels have a beginning and an end, a top and a bottom. We are comfortable navigating tunnels.
By adding a label to a collection of related notes, you can more easily think of them as a coherent group. They occupy a “space” in your notes (and in your mind) that makes them easier to examine, connect, share, and refer to. In this way, tags act like real spatial organization, without having to move anything from one place to another.
In his classic paper The Intelligent Use of Space, David Kirsh described three basic ways in which physical space can be utilized:
- To simplify perception: such as putting the washed mushrooms on the right of the chopping board and the unwashed ones on the left
- To simplify choice: such as laying out cooking ingredients in the order you will need them
- To simplify thinking: such as repeatedly reordering the Scrabble pieces so as to prompt new ideas for words
These are the same capabilities that tags provide: they help us to perceive, to choose, and to think about novel groupings of data on the fly. But crucially, to do these things to facilitate action, not just abstract thought.
Tagging notes across different notebooks allows us to perceive cross-disciplinary themes and patterns that defy simple categorization. Tagging all the notes we want to review for a project could make our choices easier, by creating a boundary around the information we’ll consider before taking action. And tagging notes according to which stage of a project they are best suited for can improve our thinking by allowing us to focus on only the most relevant information for the given moment.
In his book Supersizing the Mind, Andy Clark describes “simple labeling” (or tags) as a kind of “augmented reality trick.” With the simple act of assigning labels to things, we invite the brain’s pattern recognition ability to identify their similarities and thereby predict what other items would fit the label too. We are essentially tuning the informational environment of our notes to highlight or suppress the features most relevant to the task at hand. Our mind shapes the environment, and then the environment shapes our mind.
By thinking of tags as virtual spaces that we can create on the fly, we recruit our intuitive sense of spatial navigation to make sense of complex, abstract topics. We are able to create more concrete conceptual structures, and use our procedural memory to navigate them.
The next question is, “What do we want to use these spaces for?”
Information mapping – tagging for the knowledge lifecycle
As useful as it is to think of tags as “virtual spaces,” this still leaves us with overwhelming complexity. Conceptual spaces are vast, ever-changing, and complex. The failure of every attempt throughout history to create a “universal taxonomy” for all human knowledge is a testament to how incredibly difficult (or impossible) this task is.
I believe that what is needed for tagging to fulfill its potential while remaining feasible is to change its function: from labeling the “conceptual meaning” of bits of knowledge (which is labor-intensive, time-consuming, and fragile), to tracking its lifecycle.
What is a “knowledge lifecycle”?
It is the series of stages that knowledge moves through on its way to becoming a finished product. The stages vary based on what exactly that finished product is, but can include:
- Identifying knowledge
- Capturing knowledge
- Verifying knowledge
- Interpreting knowledge
- Organizing knowledge
- Categorizing knowledge
- Disseminating knowledge
- Combining knowledge
- Creating knowledge
- Using knowledge
- Re-evaluating knowledge
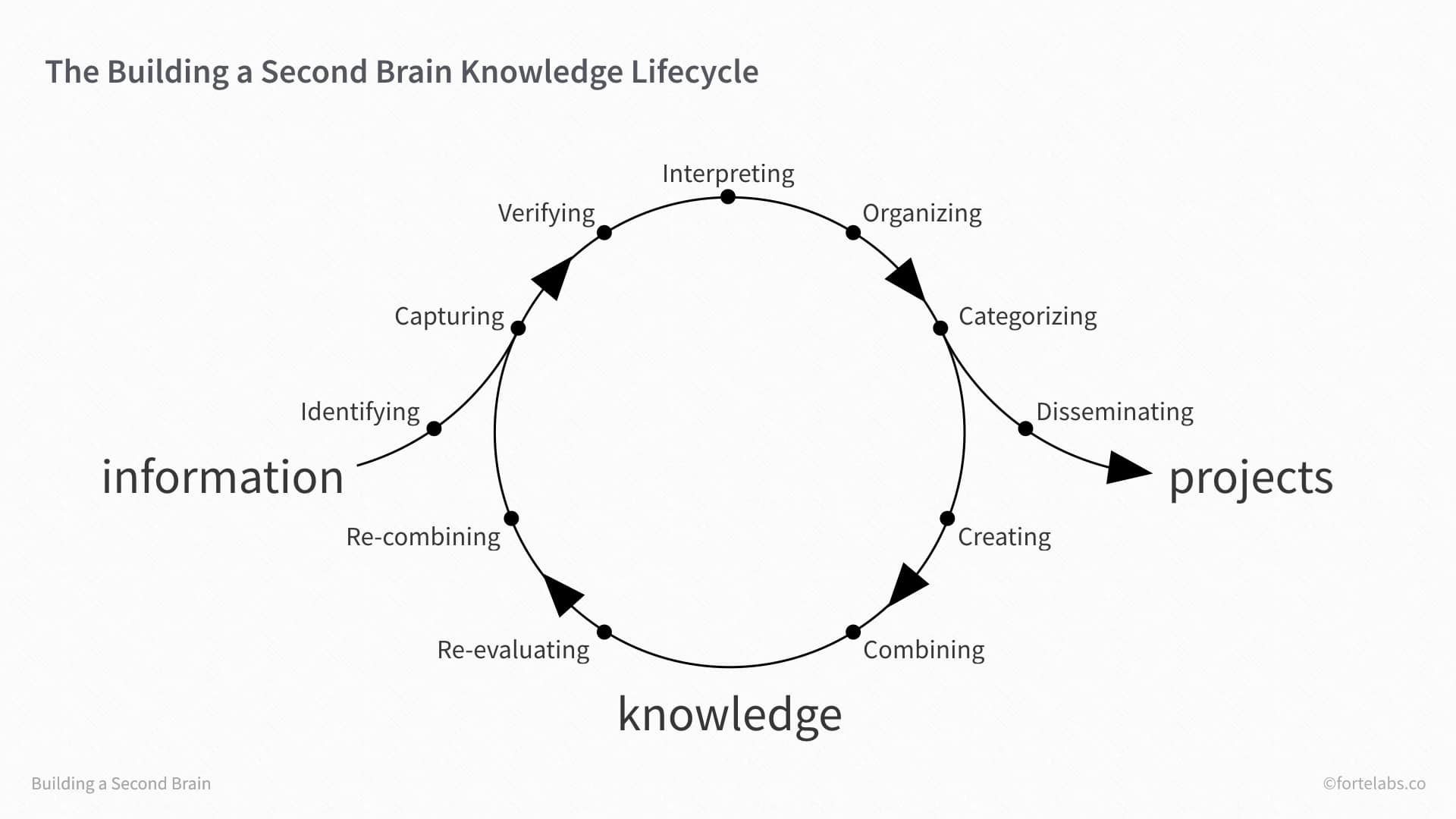
The key feature of these stages is that there are relatively few of them, and they change slowly. The products of creativity are constantly evolving and in flux, but the creative process is ancient and unchanging. By tagging according to the stages of this process, we can facilitate creativity without having to constantly redesign our organizational systems.
This idea is anything but new. In 1969, Robert Horn first published a paper outlining “information mapping” as a new approach to creating technical reference books. It was a system of principles for identifying, categorizing, and interrelating information to make learning easier in complex, information-rich environments. It was first applied to the military and to computer instruction, and has since been applied to dozens of other fields and scenarios.
At the heart of information mapping is a project lifecycle methodology. It assumes that the overarching goal of knowledge collection is to put it to use in real projects. But there is not one fixed, predetermined use. The same chunk of knowledge might be used in different ways at different times. For example:
- Initial learning
- Relearning or review
- Reference
- Briefing and browsing
- Updating with changes
- Using as job aids (preparing checklists, menus, or protocols)
All these activities may use the same bits of knowledge, but in different ways and at different levels of detail. A training manual has to be able to adapt and reorganize itself according to the needs of different kinds of readers, instead of offering a “one size fits all” version. Horn’s solution to this challenge was “information blocks” – organizing knowledge into standardized “chunks” that could be mixed and matched to suit a specific need.
Information blocks replaced paragraphs as the fundamental unit of meaning and presentation. Unstructured information was “clustered” into information blocks with clear labels, which were linked together and further refined in the writing process.
Horn and his collaborators identified 40 types of information blocks that could be categorized as one of seven types:
- Procedure
- Process
- Concept
- Structure
- Classification
- Principle
- Fact
These types were standardized across all kinds of topics and projects. Research by Horn and others indicated that about 80% of virtually any subject matter could be classified using this system. It was found that by chunking a body of information in this way early on in a project, there were tremendous benefits at every subsequent stage.
Information mapping was, on the surface, designed to make writers’ jobs easier, specifying standardized ways of gathering and presenting the right information for a given document. But it also made the readers’ job easier. With each information block labeled according to its type and purpose, readers were able to scan a block and quickly understand its content and structure. This allowed them to customize the learning process: they could read from beginning to end if it was their first pass, or go directly to the block most relevant to their needs if they were already familiar with the subject. The labels made it easier to manage the intermediate stages of what they were reading, increasing reader’s confidence in their ability to understand and make use of the text.
Information mapping was an important step toward “Just-in-Time Learning.” Instead of giving readers a massive text and expecting them to hold it all in their mind until some future, unspecified date, information was structured so that it could be retrieved quickly and efficiently just as it was needed.
What can information mapping teach us about tagging? Decades of research in this field have shown that the best use for labels is as an output mechanism, not an input mechanism. Horn’s breakthrough was distinguishing two very different functions of information – learning and reference – and recognizing that we needed to enable flexible, dynamic ways of re-organizing blocks of information to suit these different needs.
By labeling our notes when they are being used, instead of when they are created, we move the work of tagging as close as possible to the problem it is meant to solve. And by making that work conditional on the execution of a project, we ensure that every bit of effort spent in tagging is put to use.
How to use tags effectively for personal knowledge management
Building on that foundation, these are my four recommendations for how to use tags effectively in personal knowledge management.
#1 Tag notes according to the actions taken or deliverables created with them
My first recommendation is to change the function of tags from trying to describe broad themes like “psychology” and “investing” to tracking the use or function of a piece of information. This could include tagging the note:
- By action – What actions have you taken (or will you take) with this note?
- By deliverable – What have you used (or will you use) this note to deliver?
- By stage of your knowledge lifecycle – Which stage is this note currently in (or does it best belong to)?
Tags should answer the question “Is this relevant to my current need?” just enough to make the next action clear. Don’t let your ideas get bogged down in layers of categories and classifications. Speed them through your creative process and out into the real world.
Here are a few examples of tags that have been applied according to the use or function of a chunk of knowledge:
- Tags for [reviewed] and [added], for tracking which notes have been reviewed for a deliverable, and which have been incorporated into it
- Tags that designate the kind of information a note contains, such as [content], [admin], and [meeting notes]
- Tags that track the status of notes through a workflow, such as [inactive], [active], [next], and [completed]
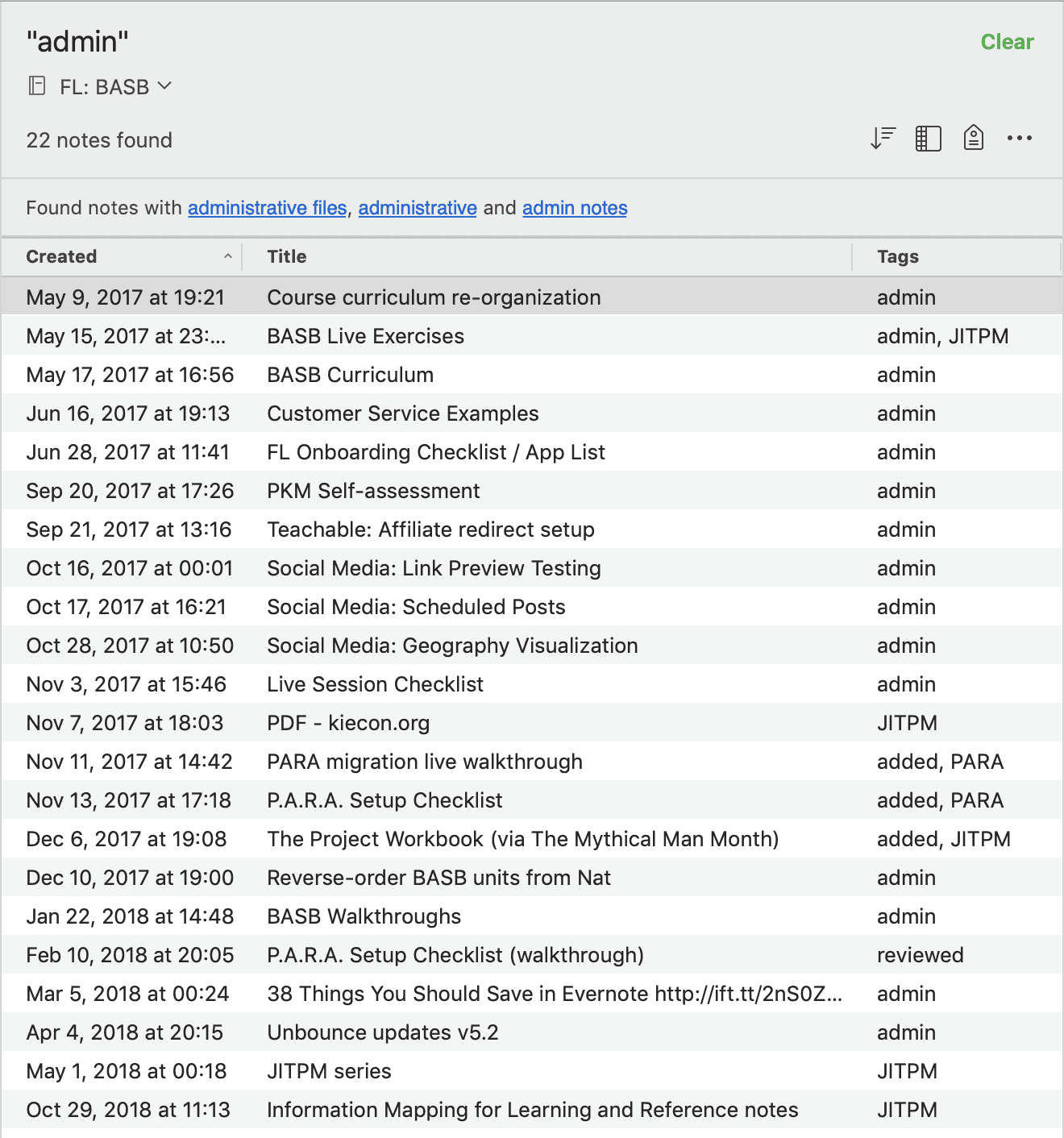
Here is an example of notes collected over the course of a year related to my online course Building a Second Brain. In the right-hand column you can see a few different kinds of tags that I use to segment this stream of notes into distinct types:
- [reviewed] means that I’ve looked it over and considered it for use in the course; [added] means I’ve incorporated it into the course in some way
- [admin] designates notes that don’t contain subject matter content, but are used for planning or technical information
- [PARA,] [PS], and [JITPM] refer to the three main parts of the course, allowing me to only consider notes for one at a time
- [basb] designates notes that I’d like to consider for the book I’m writing on the same topic; this allows me to “extract” a subset of notes for a different project, without removing them from this notebook
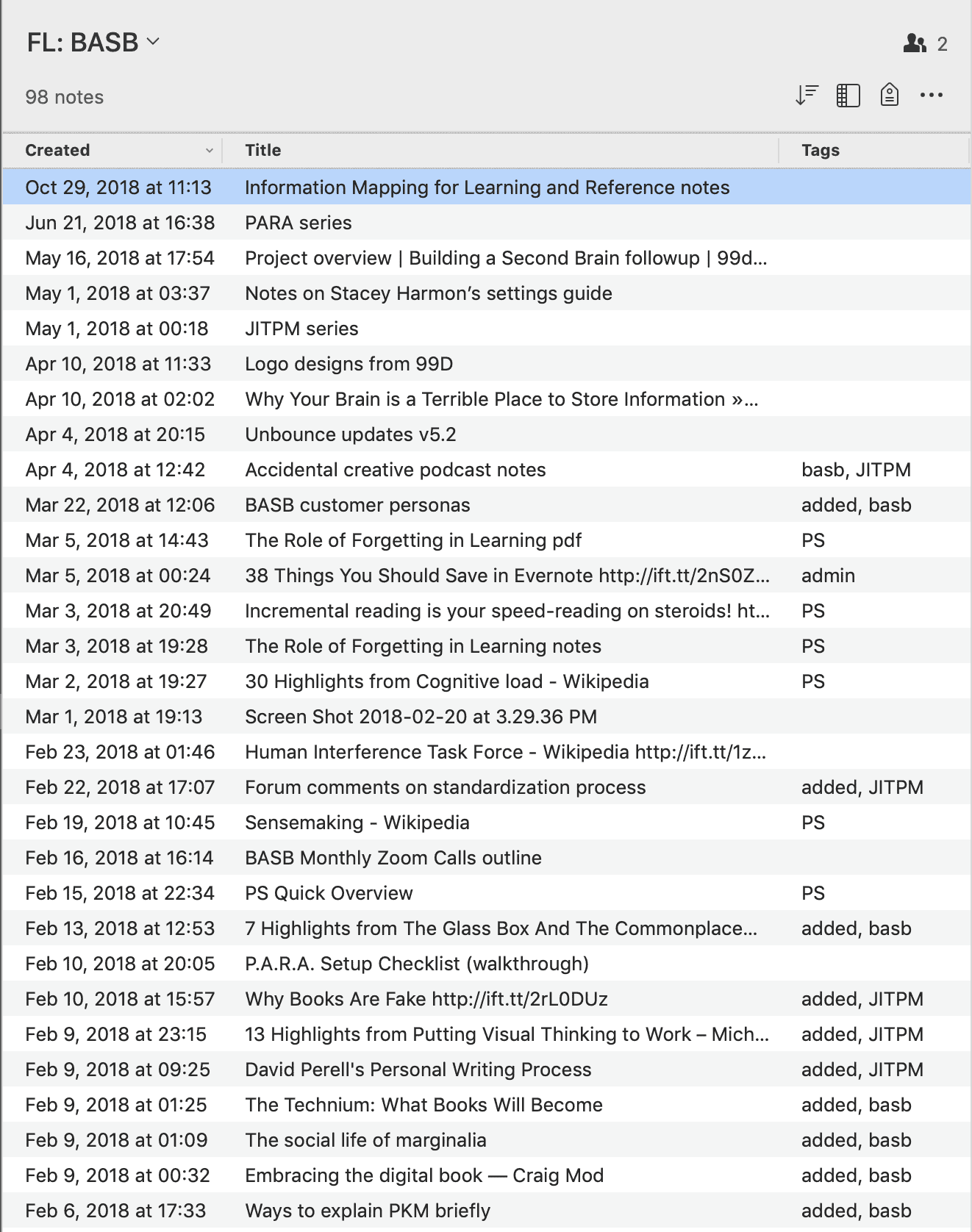
Notice that these tags don’t tell me what each note contains, or try to label them with every possible association. All they do is facilitate their incorporation into a concrete project, which is my online course. Because there are so few tags needed, I can use a few different kinds of tags at once without cluttering the notebook.
I can perform a search for one of these tags, and click this button to show only results from this notebook:
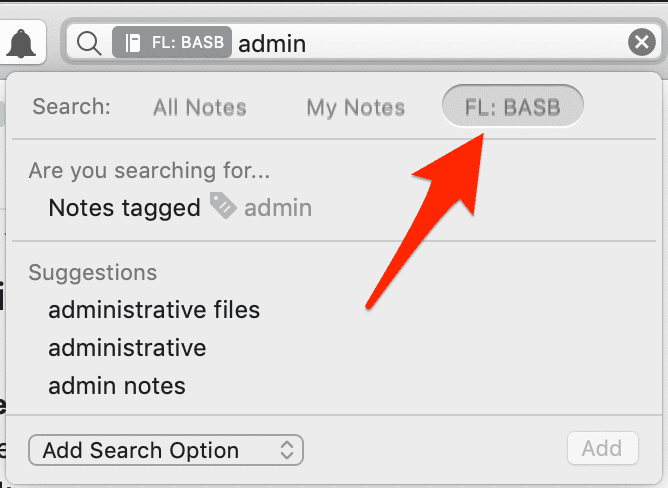
I am shown only notes with the [admin] tag within this notebook:
This use of tags is reminiscent of the “kanban” cards in Toyota’s just-in-time manufacturing system. Instead of long, complex forms detailing every part in a bin, a simple card reveals at a glance the most important things: what it is and where it goes.
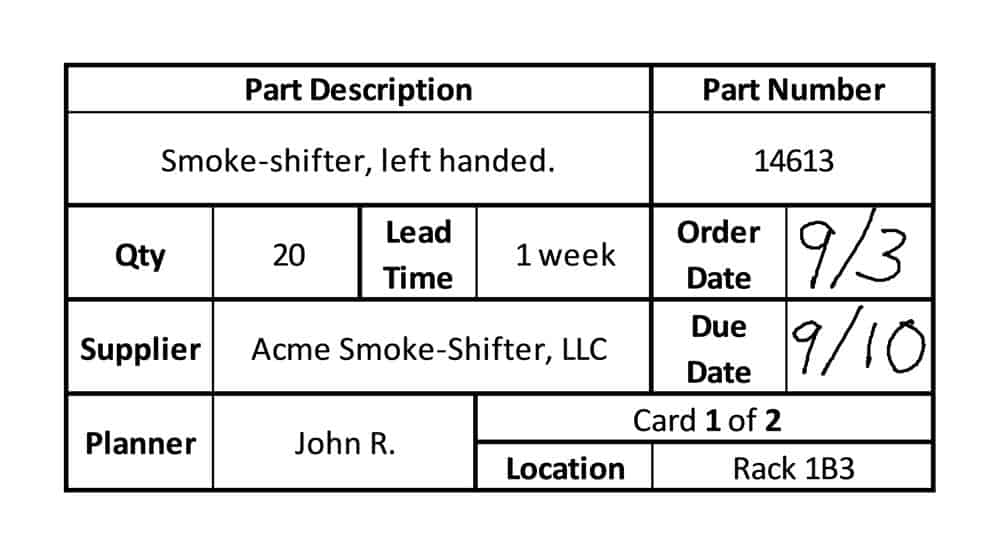
Why did Toyota create such a system of cards? Why couldn’t each part simply be placed on the assembly line in the correct order?
In post-war Japan, there were not enough factories and not enough demand to justify dedicating an entire line to one model of car, as was done in the U.S. with Ford’s Model T. The small batches of different kinds of cars that the market demanded required them to create networks of production, with different lines overlapping and sharing the same machines. One of the uses of kanban cards was to track an item through the factory regardless of which machines it passed through, in what order, and at what speed. Each item was “tagged” with its current state, so there was never any doubt as to how it should be handled
This is much the same situation we face today as knowledge workers. We rarely have enough demand for a single activity to dedicate ourselves solely to it, but instead work on an ever-changing mix of different projects and activities that wax and wane unpredictably. And these activities use the same scarce resources – our intellect, time, energy, and skills.
We should use tags in the same way that Toyota used kanban cards: to create intertwined networks in which the right “part” (or note) can be pulled from our “inventory” (or knowledge collection) at just the right moment. I should be able to capture a note today while reading a book on financial planning, and know that it will show up when I need an insight into that subject, whether that is next week, next month, or next year. The tags should remember exactly where I left off, so I don’t have to.
With tags, we have the opportunity to network our knowledge. But these networks shouldn’t be merely conceptual. They should be networks of production, pushing our ideas through our creative process and into the hands of people who can benefit from them.
This approach to tagging addresses each of the pitfalls of tagging I identified in Tagging is Broken:
- Tags should be easy to remember: since there is a limited number of actions you take with your notes, you have only a small number of options to remember
- Tags should be easy to decide on: it is usually easier to decide how a note is going to be used, rather than what it means or what it’s about
- Tags should be concrete: tagging according to actions and deliverables is far more concrete than theoretical categories
- Tags should enable the right behaviors: in this case, using tags to manage the stages of a workflow enables the productive use of knowledge, instead of mere cataloguing
- Tags should be forgiving: by maintaining tags as a supplement to a hierarchical organizational system, we reap most of their benefits without having to adhere to them perfectly
#2 Add structure slowly, in stages and only as needed, using accumulated material to guide you in what structures are needed
It is very tempting when organizing knowledge to decide on one kind of structure upfront, and then stick to it no matter what. Although there are benefits to consistency, when it comes to personal knowledge management, the most important priority is that it suits your day to day needs. Even the perfect organizational system, if you stop using it, is not perfect.
One of the most valuable features of digital information is that it is highly malleable. It can change form almost instantaneously, with nothing more than a few clicks or taps. We can take advantage of this malleability by adding structure incrementally, in small steps, as our knowledge of a subject accumulates and our needs change.
For example, if I become interested in learning Spanish for a vacation, I might save some useful Spanish words I learn to my “Travel” notebook. No structure is needed at this point, because everything I know about the topic is contained in one note.

But let’s say that I have such a good trip, I decide I want to explore the possibility of moving to Mexico. I start collecting notes with travel gear, blog posts explaining how to rent an apartment, options for cell phone plans, visa application forms, and guides on which credit cards to apply for, among other things. That original “Spanish vocab” note is now just one among many notes. The usage of that knowledge has changed. At this point, it makes sense to create a new notebook called “Move to Mexico” (a “project” according to my PARA methodology) and move these notes into it.
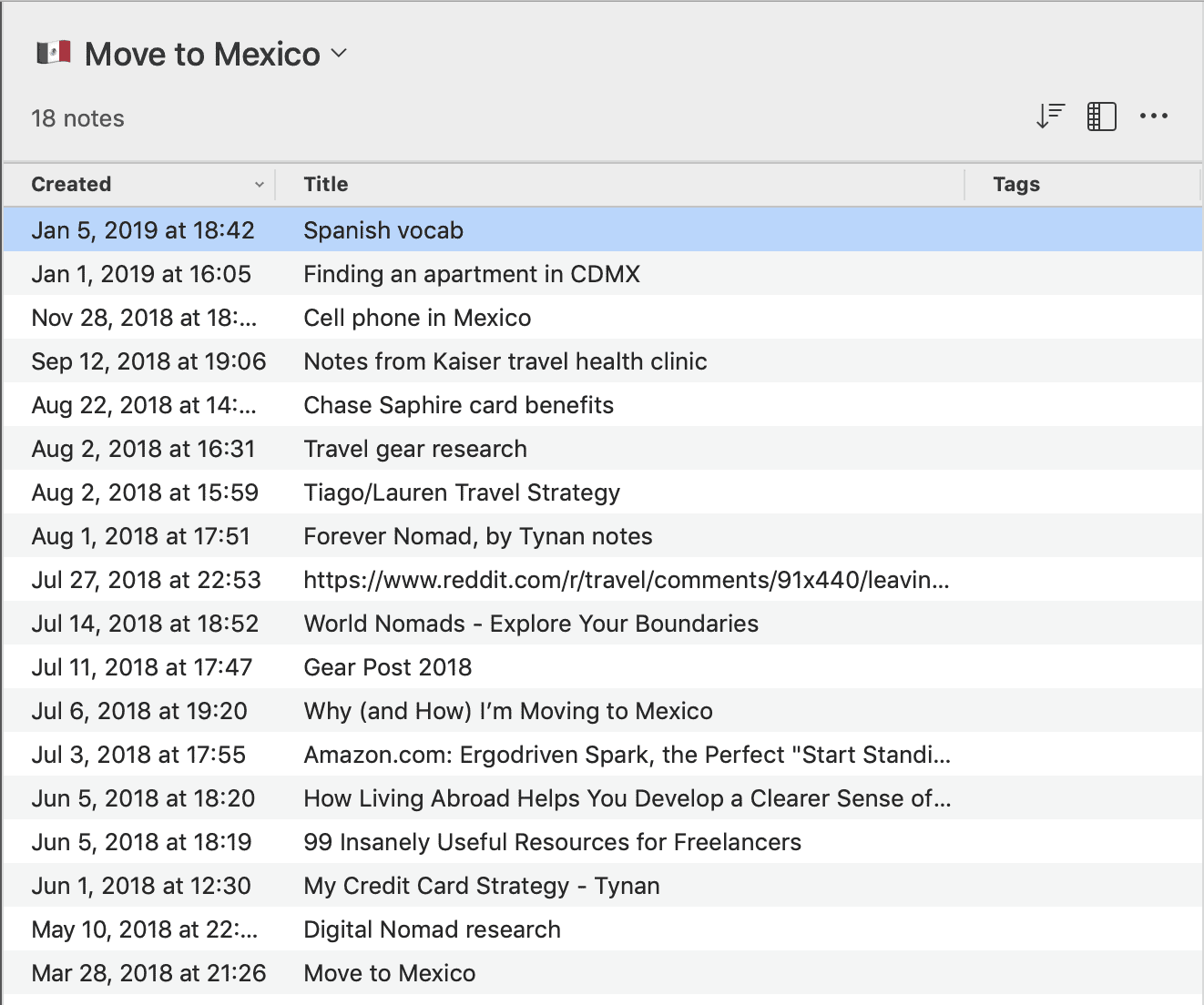
After a few months of research, I may have gathered several dozen notes, and the notebook might be starting to get too cluttered to find what I’m looking for. At this point I can easily “segment” the notebook by tagging notes according to broad types like [apartment], [language], [logistics], [financial], [gear], [research], [writing], etc. I suggest using a small number of types so you can see your options at a glance just by looking at the Tags column.
Clicking the “Tags” header at the top of the right-hand column will sort the notes according to type, which allows you to see related notes in one place while keeping them in the same notebook:
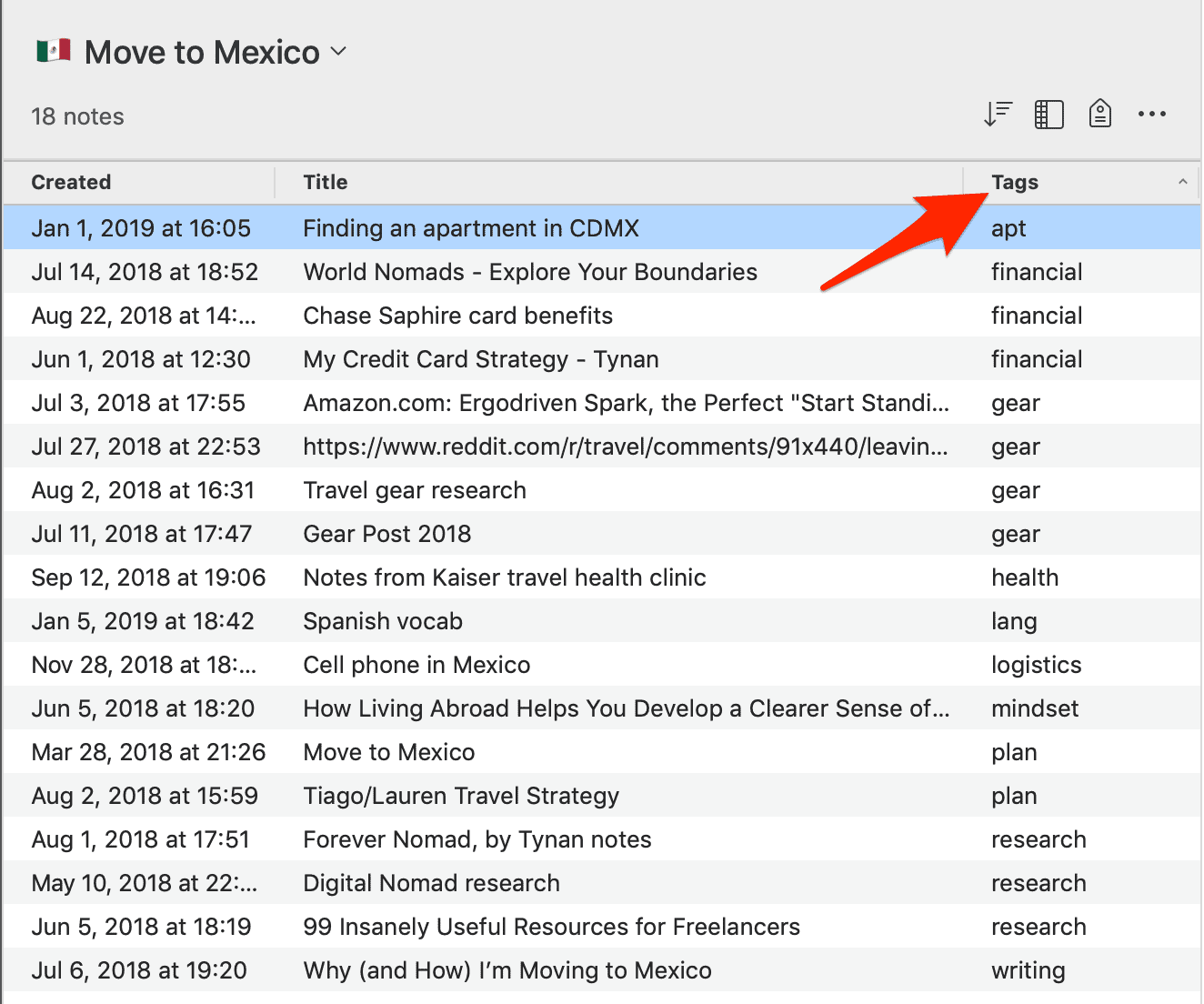
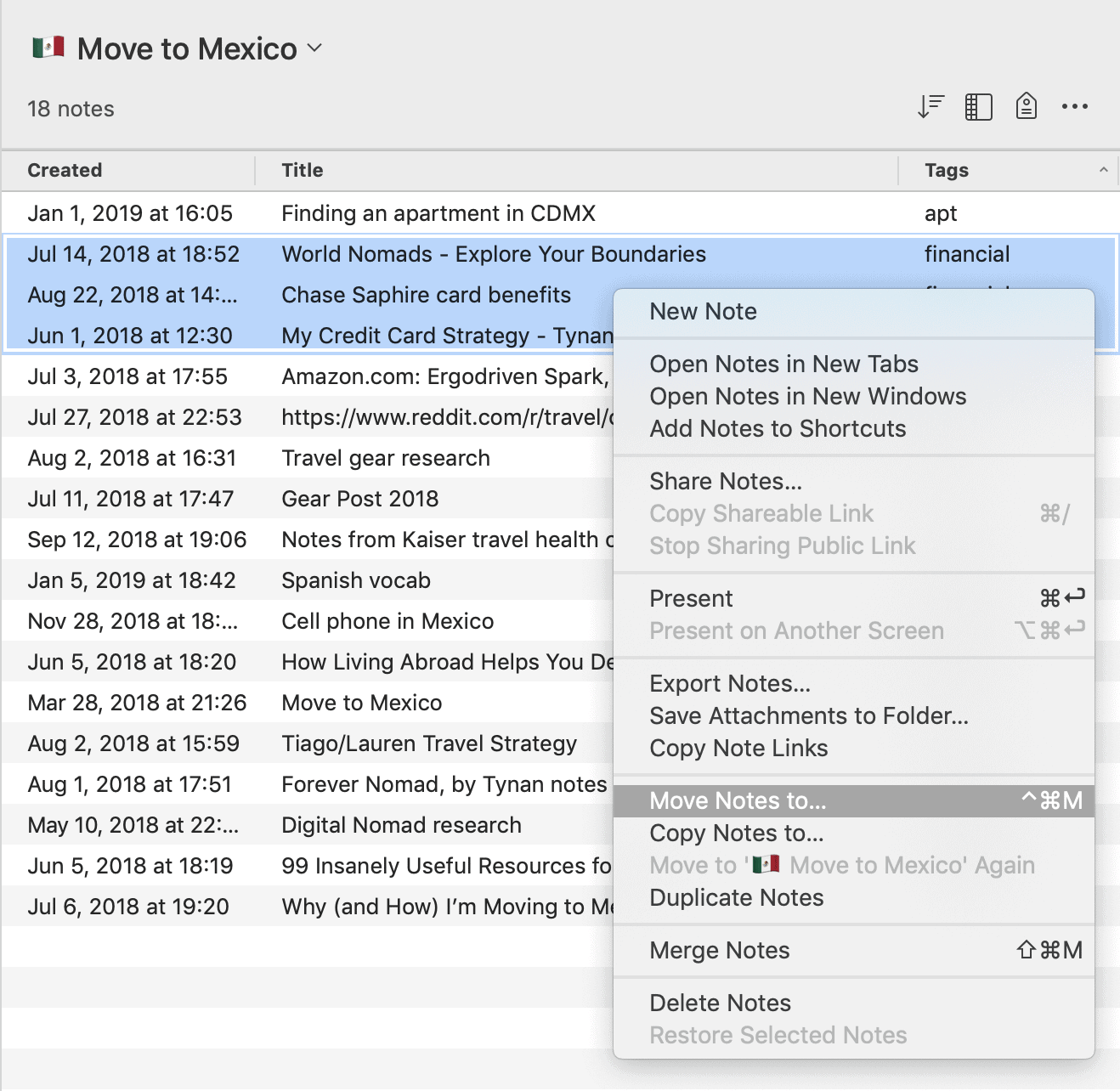
Let’s say a few months pass, and now I’m actually living and working in Mexico City. At this point, a single notebook no longer covers the many facets of life in a new city. I’ll need to create several new notebooks, including projects like “Find gym” and “Activate cell phone service,” areas of responsibility such as “Apartment,” and resources like “Mexican food” and “Spanish language.”
It wouldn’t make sense to have created all these notebooks upfront, when I had so little to store in them. It is effortless, once the relevant categories have revealed themselves, to move notes into these new notebooks (right click > Move notes to…):
With this approach, I’m only adding as much structure as is needed for a given stage of my learning journey. This helps ensure that I’m spending most of my time engaging with the content, instead of maintaining a complex organizational system. You would think that adding the structure later is more difficult, but in fact it is easier: instead of trying to guess which categories will be needed, I can look at what I’ve already collected and pick the categories that perfectly suit it.
How do you know which divisions or categories to use? Again, instead of trying to guess that upfront, start with the laziest approach: simply collect whatever seems interesting on a given topic. When the time comes, and only when the time comes, look at what you’ve already captured organically and look for patterns. The best time to do this is when starting a project that might draw on these notes, because often the divisions will come from the project itself.
For example, let’s say you’re hired by a company to improve their hiring process. You might have dozens or even hundreds of notes related to hiring if that is a service you provide. But the way the project is organized will often tell you what parts or stages are most relevant. Perhaps the contract is split between “Résumé collection” and “Interviewing.” By reviewing your notes retrospectively and tagging them with these two labels, you can very quickly re-orient your notes related to hiring along these lines. Using an organizational scheme that matches the structure of the project will make that project much easier to execute.
I’m constantly surprised at how clearly divisions appear, as long as I’m starting with a batch of real notes. If I try to theorize about the correct tags before I’ve actually collected anything, it’s always off the mark. The magic of digital information is that it is easy and frictionless to make such retrospective changes. This kind of backward-looking reorganization also allows us to jump into new topics much faster: instead of spending my precious energy getting set up when I’m excited about something, I plunge directly into the heart of the subject, capturing whatever seems interesting and trusting that I can sort it out later.
There is another benefit to this method: it is perfectly okay to not tag a note at all. So long as you’re not using tags as your primary organizational system, there is no chance that a note left untagged will completely fall through the cracks. It will always be right there in the notebook where you left it. This avoids the frustrating experience of trying to force yourself to think of a tag for a note, even when nothing comes to mind, because otherwise it will be lost completely.
The lesson here is to not create structure before it’s needed. By adding just enough structure, at just the right moment, the work required to maintain it will always feel like a welcome relief, instead of a heavy burden.
#3 Tag notes according to their internal, external, and social context, and status
In their book The Science of Managing Our Digital Stuff, from which all the studies in this article are drawn, Ofer Bergman and Steve Whittaker identify the four attributes of a piece of information that can be used to describe its “context.”
- Internal context includes the thoughts, feelings, associations, concerns, and considerations you have about a note
- External context includes the other items that you are dealing with while interacting with a note, such as other notes, documents, folders, or apps
- Social context refers to other people who are related to the note, such as project collaborators, the person who recommended the source, or who it was shared with
- Current status refers to any actions taken with the note, or any deliverables it was used in
These attributes are universal in that they apply to any kind of note from any source, yet are also easy to apply. They don’t try to describe the content of the note; only its context. These aren’t abstract labels requiring intensive thinking. They are simple questions that can be answered by looking around at what you’re doing. They can be added incrementally and as needed. They will enable you to more easily return to the state of mind you were in the last time you interacted with a note, using contextual clues that our minds are made to understand.
Here is an Evernote note template that can be used to add these four kinds of context at the top of any note, including a short video I created on how to save the note as a template to your account. Here’s an example of the template filled out:

#4 Develop customized, profession-specific taxonomies
The history of organizing information is largely concerned with “taxonomies” – hierarchical systems for categorizing information in one all-encompassing model.
Passionate debates about which is the “correct” taxonomy go back millennia. Aristotle believed that knowledge could be classified according to its substance, quantity, quality, relation, place, time, position, state, action, & passion. Francis Bacon categorized all human knowledge into memory (i.e. history), reason (i.e. philosophy), and imagination (i.e. fine arts). The 20th century Indian librarian Shiyali Ramamrita Ranganathan argued that any document could be defined according to its personality, matter, energy, space, and time.
The goal has always been to create a single, completely comprehensive ordering of knowledge that any future idea can be placed into. But over many hundreds of years, as our knowledge has exploded in size and complexity, the possibility of a universal taxonomy has faded. It is now quite clear that any such taxonomy will either be too broad to be useful, or too narrow to be universal. The dream of a universal taxonomy is dead.
But for specific fields and professions, it is clear that taxonomies have tremendous value. Biology would be a hopeless tangle of overlapping specialties without the Linnaean taxonomy. Chemistry would be futile without the periodic table. Trends in art would be impossible to make sense of without schools and periods. As long as you can rely on a “controlled vocabulary” of agreed upon terms, it makes a lot of sense to put everything into a category.
A student in one of my courses explained his system for writing scripts (emphasis mine):
“If you know what the constituent parts are of your particular art form, you can collect “snippets” of evocative ideas for any one of them in a single notebook and use tags to label them. So, for example, I have a “Film Ideas” folder where I store ideas and then tag them with one of the following labels:
- C = description of Characters who could be used in a story.
- L = interesting and visual Location.
- O= curious or evocative Object.
- S = loaded or revealing Situation.
- A = unusual or revealing Act.
- T = any Theme that intrigues you or that you see embodied in life
Then I can see all of these notes side by side and if any particular combination of elements sticks out to me, I have the beginnings of a story idea.”
Such a taxonomy can be even more specific than your field or profession, since you are the same person recording and retrieving this knowledge. They can be “personomies,” or personal tag vocabularies, containing the terms that you use to refer to the parts of your work. This personomy is something you will have to develop yourself, but your profession or industry is a good place to start.
The scalability of tagging
In my experience, it is only necessary to use tags when your collection becomes formidable. After nearly 10 years of note-taking and more than 8,000 notes created, I am just starting to seriously run up against the limits of a no-tagging system.
This finding has been echoed in the research. In the 1960s and 1970s, IBM conducted a series of experiments with their new Storage and Information Retrieval System (STAIRS), one of the first systems in which the computer could search the entire text of documents. They found that search accuracy could run as high as 75 to 80%. They happily proclaimed the “death of meta-data.” Why spend time and money having humans index documents when the computer could just search everything?
But there was a fatal flaw in the experiments. They used small collections containing only a few hundred documents. It was assumed that these results would apply equally well to large collections, as long as they had enough computer power. But it was a language problem, not a computer problem.
In the 1980s, researchers David C. Blair and M.E. Maron tested a full-text litigation support system containing about 40,000 documents with 350,000 pages of text. The lawyers depended on this system to retrieve all the documents that might help them win their cases. But Blair and Maron showed that recall averaged only about 20%. The system was retrieving only about 1 in every 5 relevant documents! And this was with trained researchers.
The trouble is that language has numerous, often vague, overlapping mappings to ideas. As David Blair recounts from a real example, a system with 1,000 documents contained 100 that contain the word “computer,” with the word being used 10 different ways. But in a system with 100,000 documents, 7,100 contained the word, and it was used in 84 different ways. The number of possible meanings and interpretations explodes almost as fast as the information itself.
This is where tags come in. They can provide the essential missing piece of data that computers still cannot determine: what a note is about. As long as you follow the recommendations in this article – using tags to track where a chunk of knowledge is in the knowledge lifecycle, adding structure and tags slowly and incrementally, and adding contextual data to notes – you can create paths of action for your future self to follow, without being burdened by rigid bureaucracy.
In the context of personal knowledge management, we need both hierarchies and networks. Notebooks allow us to gather a batch of related material in one place, and look for patterns and associations between the things we’ve collected. Tags add a network to this hierarchy – a distribution network for more efficiently exporting our ideas into the external world.
Ambient findability
“Ambient findability” is a term coined by information architect Peter Morville in a book of the same name. It describes the practice of creating environments where relevant information can be found and used, whether that is a library or a smartphone. When an item is “findable,” it means that it is easy to discover and locate.
The key skill in navigating such an environment is wayfinding, which refers to “the series of things people know and do in order to get from one place to another, inside or outside.” It is a skill we developed to navigate physical environments that we’ve since adapted to virtual environments. But the virtual worlds we’ve created lack the natural landmarks we rely on in the natural world. They lack trees, rivers, seashores, and paths. In the digital world, we have to create them ourselves, out of words.
But the way we’ve used tags in the past comes from a different era. Morville recounts his memories of “online searching” at the University of Michigan’s School of Information and Library Studies, in the ancient epoch of 1993:
“We searched through databases via dumb terminals connected to the Dialog company’s mainframe. Results were output to a dot matrix printer. And Dialog charged by the minute. This made searching quite stressful. Mistakes were costly in time and money. So, we’d spend an hour or more in the library beforehand, consulting printed thesauri for descriptors, considering how to combine Boolean operators most efficiently, and plotting our overall search strategy. A computer’s time was more precious than a human’s, so we sweated every keyword.”
Elaborate, precise tagging systems made sense at that time, when every operation cost money. But the challenge today is not to conserve computer power, but to spend it. Instead of wasting hours of precious human time with laborious tagging just to make a computer’s job easier, we should generously spend the computer’s power to make our job easier.
Thanks to Andrew Brož, Chris Harris, Sachin Rekhi, and Jessica Malnik for their feedback and contributions
Follow us for the latest updates and insights around productivity and Building a Second Brain on X, Facebook, Instagram, LinkedIn, and YouTube. And if you're ready to start building your Second Brain, get the book and learn the proven method to organize your digital life and unlock your creative potential.